Accelerate Tetra Data availability as external tables in Snowflake

The Tetra Scientific Data Cloud has adopted the modern data lakehouse architecture. It brings together ACID (atomicity, consistency, isolation, and durability) compliant transactions offered by data warehouses and large-scale object storage capability for structured, semi-structured, and unstructured data offered by the data lake architecture. The data lakehouse architecture also offers advanced functionalities such as schema evolution, customized partitioning, sophisticated compression techniques, co-resident metadata with data, and features such as time travel. These advantages provided by the data lakehouse architecture ultimately contribute to reducing storage needs, transferring less data over the network, and loading only required data into memory for processing. As a result, users experience expedited query execution times.
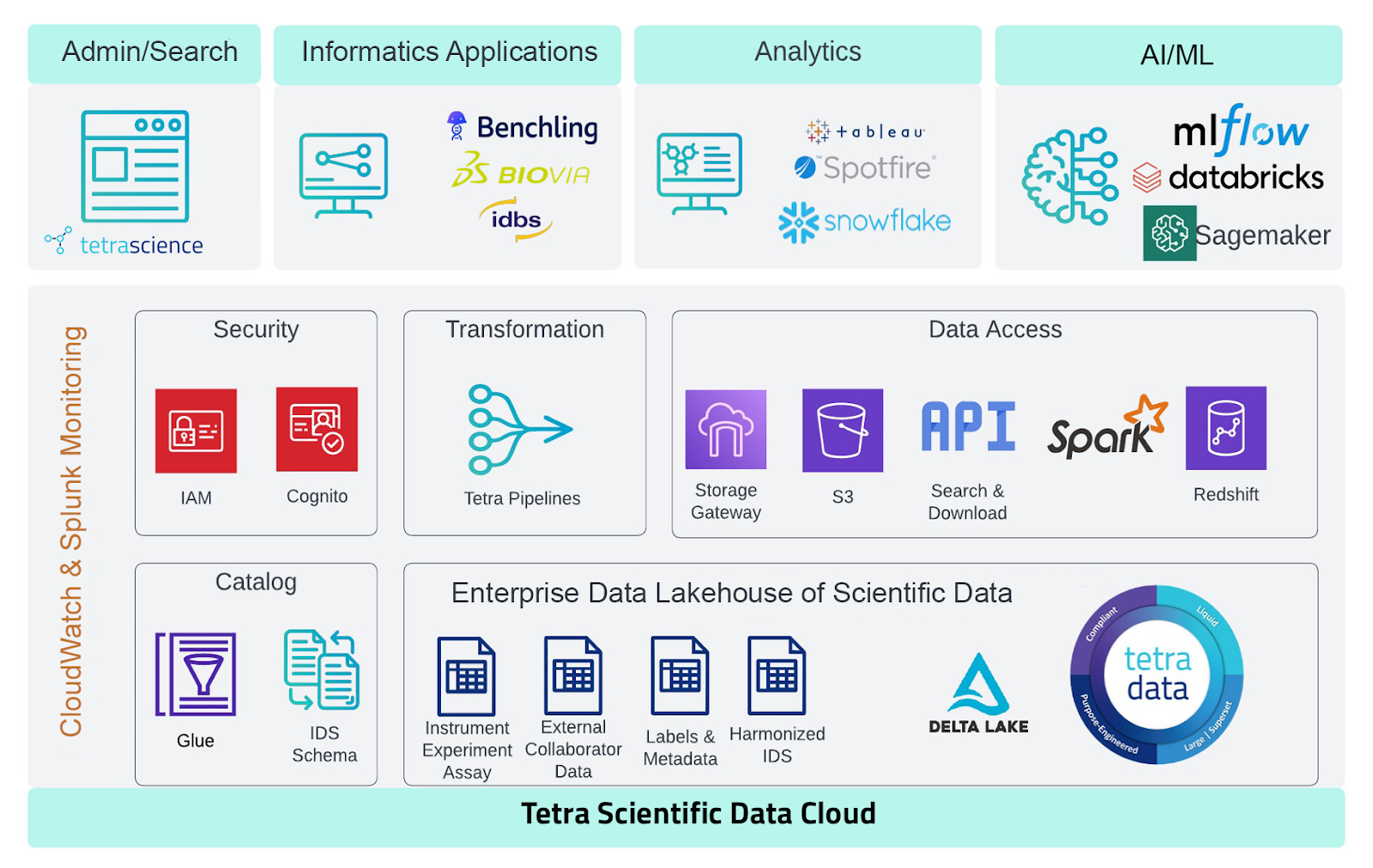
By adopting an open table format, the Tetra Scientific Data Cloud can be leveraged in workflow automation, AI, ML, and BI workloads with high query performance. The platform eliminates the requirement to physically relocate organizations’ engineered scientific data (Tetra Data). Tetra Data is presented as a data model within third-party data warehouses such as Snowflake and AWS Redshift, while all physical Tetra Data remains stored within the Tetra Scientific Data Cloud.
The Snowflake platform, with its ability to scale object storage and compute layers independently, supports multiple workloads, such as data warehousing, BI, and ML, as well as custom applications and data sharing. Availability in all major public clouds allows Snowflake to make all data available within an organization by centralizing data in Snowflake storage or alternatively storing as external tables when governance and other workload compulsions mandate such an approach. Combining data from a multitude of instruments with other corporate data in biopharmas helps accelerate drug development cycles through both internal and external collaboration.
Analyzing query performance
One of the primary and obvious reasons for moving data from the Tetra Scientific Data Cloud to Snowflake is to enhance query speed. The graphic below displays benchmark tests conducted by the TetraScience product development team, comparing query speeds between Tetra Data copied into Snowflake (SF-Copy) and Tetra Data exposed as external tables in Snowflake (SF-Delta).

Tetra Data exposed as external tables experiences marginally longer query execution times due to network related effects when compared to tables stored internally in Snowflake. As depicted above, the query performance is better for most SQL operations when data is copied into Snowflake.
The query execution times for Tetra Data exposed through external tables can be improved by optimizing individual data file sizes, employing partition columns and keys for efficient table scanning, and utilizing Snowflake’s Results Caching feature for repetitive queries. The overall read efficiencies offered by the data lakehouse architecture results in external tables providing acceptable query times, negating the necessity to move and administer the data in Snowflake storage.
There are reasons beyond just query execution times that one needs to consider when making Tetra Data available through Snowflake. Exposing Tetra Data hosted in the data lakehouse as external tables provides the following advantages over physically copying the same into Snowflake:
- Reduced storage and ELT costs
- Reduced data redundancy
- Simplified update management and evolution of schemas
- Access to real-time data
- Ease of data sharing
- Consistent data governance and compliance
- Support for data formats and specialized applications
Advantages of Snowflake external tables vs. Snowflake copied tables
This section delves deeper into the above-mentioned key advantages of offering Tetra Data as external tables within the Snowflake environment rather than physically relocating (i.e., copying) the data to Snowflake. The graphic below illustrates the flow of Tetra Data from the Tetra Scientific Data Cloud to downstream Snowflake accounts.

Reduced storage and ELT costs
Using Tetra Data as external tables in Snowflake allows data to reside in the Tetra Scientific Data Cloud without physically transferring it to Snowflake storage. This can be a more cost-effective approach, especially with large volumes of data, as users incur expenses only for storage in the source system, not for additional Snowflake storage.
For example, instruments using the latest next-generation sequencing (NGS) techniques produce hundreds of terabytes of data. Replicating this data across multiple storage systems and managing ELT pipelines for data migration is costly. The use of Tetra Data as external tables simplifies the data stack, eliminating the need for additional investment and consumption costs associated with ELT applications.
Reduced data redundancy
The Tetra Scientific Data Cloud allows bidirectional communication for writebacks from various scientific tools like electronic lab notebooks (ELNs) and third-party applications through SQL and REST API interfaces. The diverse nature of analyses, workflow integration, and scientific use cases necessitates deep integration of the Tetra Scientific Data Cloud with other applications in the early drug development and manufacturing lifecycle.
Instead of duplicating data in Snowflake, leveraging Tetra Data as external tables in Snowflake allows querying and processing data directly from its original location. This reduces the need for data replication, minimizing redundancy and ensuring data consistency and integrity across systems. Large organizations typically use multiple compute environments (e.g., Databricks, AWS Redshift), and duplicating Tetra Data across each of these systems would require significant resources and costs.
Simplified update management and evolution of schemas
As the instrument landscape evolves, adapting new versions of Tetra Data schemas for data harmonization and other scientific workflows is necessary. Large life science organizations deal with thousands of scientific instruments and systems, each with its evolving schema, but Snowflake does support schema on read. Manually creating and adjusting these schemas in the Snowflake environment is resource-intensive and an unnecessary duplication exercise.
Tetra Data available as external tables eliminates the need to manually adapt and change schemas in Snowflake. This aids scaling, simplifies the management of updates, and minimizes disruptions in downstream analytics, ML, and integrated scientific workflow implementations.
Access to real-time data
Using Tetra Data as external tables facilitates real-time or near-real-time access to data as it’s updated in the Tetra Scientific Data Cloud. There’s no delay caused by data loading processes, ensuring the most current data is available for analysis. The Tetra Scientific Data Cloud can host real-time data from IoT agents and KEPServerEX agents, moving data to storage for downstream enrichment and harmonization upon arrival. Moving rapidly updating Tetra Data to Snowflake storage would necessitate using Snowpipe, incurring extra costs and pipeline maintenance. Leveraging Tetra Data through external tables eliminates the need for this.
Ease of data sharing
Using Tetra Data through Snowflake’s external tables simplifies data sharing across multiple Snowflake accounts or with external partners, as the data remains in its original location. Tetra Data as external tables circumvents the need for exporting and importing data, enhancing collaboration efficiency. Complex ELT and Snowpipe pipelines do not need to be maintained, and all Tetra Data available in the Tetra Scientific Data Cloud can be immediately shared.
Different domains within an organization may have varying levels of autonomy in selecting data product stacks. By retaining Tetra Data (the engineered scientific data) in the Tetra Scientific Data Cloud as a single source of truth providing all the domains in the organization with a common denominator between teams. These autonomous domains can implement data products with lineage, ownership, federated governance, and self-service capabilities for scientific analysis.
Consistent data governance and compliance
Making Tetra Data available as external tables simplifies data governance by offering a single source of truth. It reduces the complexity of managing data in multiple locations and systems, thereby improving governance and compliance efforts. The Tetra Scientific Data Cloud is an industry vertical–focussed platform, offering the necessary depth of adherence to various industry specific compliance requirements such as 21 CFR Part 11, GxP, ALCOA principles, GAMP 5, and Annex 11. With numerous departments and functions dependent on the same scientific data, maintaining a single version of the truth is crucial for data traceability and GxP compliance. For instance, the FDA, through its drug inspection program, has pursued official/voluntary action against various organizations for data-related breaches more than 900 times in the last decade alone, underscoring the importance of data integrity and access controls.
The Tetra Scientific Data Cloud stores all incoming instrument data in its raw format, along with changes applied through data transformation workflows and archival processes, as mandated by the FDA in its electronic records requirements. The Tetra Scientific Data Cloud also supports the Verification and Validation (V+V) process, a key requirement mandated by FDA. Moving data into Snowflake would detach all the compliance related controls on Tetra Data and would require significant compliance reimplementation and revalidation effort.
Support for data formats and specialized applications
Making Tetra Data available as external tables supports various file formats and data sources, enabling organizations to work with diverse datasets and unstructured data like images. Users can access both JSON file formats and data stored in the data lakehouse using SQL and a REST API.
Unlike Snowflake, the Tetra Scientific Data Cloud not only supports SQL passthrough but also allows bidirectional orchestration, which is leveraged by Tetra Data Apps to trigger pipelines and data transfer of various file types like WSP (workspace) from the FlowJo application and even microscopy image files like ZEISS .CZI. Moving such unstructured data to Snowflake and performing scientific analysis isn't straightforward (using user-defined functions [UDF]) in Snowflake as it primarily supports structured and semi-structured data.
Summary
The integration of Tetra Data into Snowflake using a modern data lakehouse architecture enables users to access Tetra Data in Snowflake as external tables, eliminating the need for physical data movement. Employing this approach helps ensure improved query performance, reduced storage costs, minimized data redundancy, simplified schema evolution, and real-time data access without compromising data integrity or compliance.
By retaining Tetra Data in its original location and accessing it through Snowflake’s external tables, this integration streamlines data sharing and supports distributed processing. It maintains a single source of truth and enhances governance efforts. Moreover, this approach addresses security concerns, compliance challenges, and data sovereignty issues.