Unlock scalable access to engineered scientific data from Athena, Snowflake, Redshift, and Databricks

In the ever-evolving world of life sciences, data is the cornerstone for the development of novel therapeutics. As life science companies seek to modernize their data architecture and harness the power of advanced machine learning (ML) and artificial intelligence (AI), they must also support and streamline existing scientific workflows.
Traditional data management tools, such as scientific data management systems (SDMSs), have limitations that hinder the democratization of data required for decision making across the enterprise. This is where TetraScience comes into play.
In this blog post, we will explore how the Tetra Scientific Data CloudTM enables customers to seamlessly consume high-quality engineered Tetra Data from any analytical or SQL tool their enterprise IT/data teams choose. We will focus on accessing scientific data from AWS Athena, Snowflake, Redshift, and Databricks. We will show how the purpose-built TetraScience scientific lakehouse enables access to Tetra Data without duplicating data.
Democratizing scientific data with Tetra Data and a scientific lakehouse
TetraScience aims to revolutionize scientific data management by capturing data from various sources crucial to scientific innovation and making it AI ready. These sources include experimental design systems, electronic lab notebooks (ELNs), laboratory information management systems (LIMSs), instrument and instrument control software, and analysis systems. Read here to learn more on how to centralize siloed scientific data from these sources to replatform raw scientific data into Tetra Scientific Data Cloud as the first step to transform data and harness its power for AI/ML.
TetraScience's lakehouse architecture is designed to seamlessly handle raw, complex, semi-structured, and unstructured data assets. This unified platform combines the capabilities of a data lake and a data warehouse, thus supporting the needs of life sciences customers at different stages of the data maturity journey—a journey with an immutable order of operations represented as a layered pyramid below.

In this blog, we will focus on data layers and primarily on “layer 2”, also known as the data engineering layer, or the layer that transforms scientific raw data into analytics/ML/AI-ready data.
Data engineering
The Tetra Scientific Data Cloud replatforms raw data, along with its metadata, to the Tetra Lakehouse, which is built on Amazon S3. Raw data can be collected from diverse sources and vendors, including high-performance liquid chromatography (HPLC) instruments and plate readers as well as analysis results, reports from contract research organizations (CROs) and contract development and manufacturing organizations (CMOs), and experiment contexts from ELNs/LIMSs.
The Tetra Scientific Data Cloud then engineers this data for analytics and AI applications, as well as the enterprise-grade lakehouse architecture that supports seamless data access. It uses transformation pipelines to engineer data into Tetra Data.
Intermediate Data Schema (IDS) framework
All Tetra Data is represented in an Intermediate Data Schema (IDS) JSON format. Tetra Data uses an IDS as a harmonized schema, translating vendor-specific information (such as field names) into a vendor-agnostic format. It standardizes various aspects of the data, including naming conventions, data types (such as strings, integers, or dates), data ranges (e.g., requiring positive numbers), and data hierarchy.
By harmonizing data into an industry-standard JSON schema, TetraScience enables organizations to seamlessly incorporate the data into their applications, create advanced searches and aggregations, and feed Tetra Data into higher layers of the data pyramid.
Tetra Data’s schematic JSON files are designed to be predictable, consistent, and vendor agnostic. They comprehensively capture all scientifically meaningful information and help ensure effortless consumption for organizations. The IDS column and attribute naming conventions are also fully in compliance with popular columnar file format conventions like parquet, orc, etc., so as to enable direct and easy ingestion and querying of IDS data by processing platforms such as Redshift, Snowflake, and Databricks.
TetraScience offers a wide range of pre-defined Tetra Data models and tools for creating custom Tetra Data models. Engineered data inherits metadata from the transformed raw data and incorporates additional metadata before being stored in the TetraScience lakehouse. This makes data retrievable and enables meaningful analytics and AI outcomes.
Tabular schema
To support customers querying Tetra Data using a familiar SQL interface, TetraScience adopts a proactive approach by providing a solution: A tabular schema is delivered for each Tetra Data’s JSON schema. This tabular schema is inherently declarative, designed to significantly simplify the querying process. Through this innovative feature, Tetra Data represented in the IDS JSON format is automatically and consistently aligned with its corresponding tabular definitions. This ensures that customers can access and work with their data efficiently and with minimal latency.
In essence, this capability empowers users to harness the full potential of SQL, enabling them to interact with their data seamlessly. As a result, the data analysis process becomes more intuitive and streamlined, addressing the complexities associated with hierarchical data queries.
Common IDS fields:
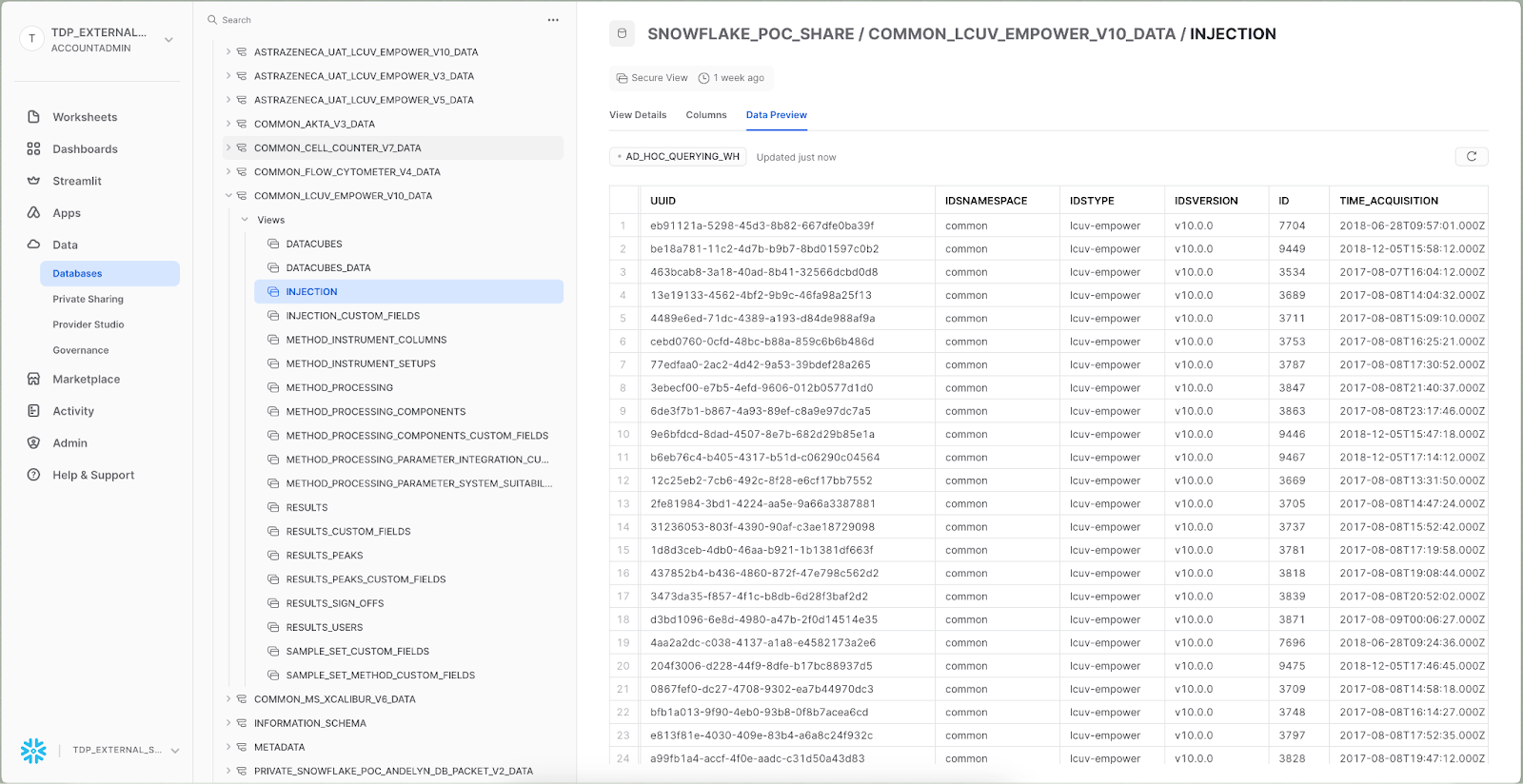
Example of an Empower IDS:

Example of a tabular schema:

File info and attributes
Besides storing data, the Tetra Scientific Data Cloud collects and manages information related to replatformed and engineered data. This information is automatically collected by Tetra Integrations at the source, inherited by Tetra Pipelines, or augmented by customers. TetraScience collects file attributes and file info and adds it to the Tetra Data
File attributes
Attributes are information annotated to raw and engineered data. These are mutable labels and immutable S3-tags and S3-metadata annotated to data. For example, metadata and labels can be used to trigger the transformation of raw data into Tetra Data or to move data from instruments to an ELN. They also can be used to contextualize the data sets with information such as sample id, assay number, and project code. Attributes are available for querying via SQL from the file_attributes_v1 table.
Example: Tags, metadata, and labels annotated to the data

File info
These are immutable data properties imposed by the Tetra Scientific Data Cloud relating to encoding, storage, data categorization, source, lineage, and trace data. This data is available for querying via SQL from file_info_v1 table.
Example: Trace data added by Tetra Empower Agent

Example: Source data added by Tetra Empower Agent

Data catalog
Each IDS schema comes equipped with a declarative tabular data model, simplifying the querying and processing of Tetra Data for various purposes, including analysis, visualization, and integrations. The Tetra Scientific Data Cloud leverages the AWS Glue Catalog as the centralized repository for storing Tetra Data table metadata. This approach ensures a consistent and standardized approach to data management across different systems and applications.
The AWS Glue Catalog primarily contains flattened Tetra Data tabular schemas and Universal Format Delta Tables, which will also be registered with the AWS Glue Catalog. These Delta Tables serve as a fundamental technology driving the transformation into a lakehouse architecture. This evolution enhances data governance and accessibility significantly.
Of particular note is TetraScience's adoption of Uniform Delta Tables. This strategic choice uniquely positions the Tetra Scientific Data Cloud to be compatible with enterprise tools that opt for either Delta, Iceberg, or Hudi as their underlying Open Table Formats. This compatibility ensures seamless integration and data sharing capabilities across a range of data management systems.
Tetra Data Schema and AWS Glue Tables for Empower IDS. Waters Empower is a chromatography data system (CDS) that controls various chromatography instruments.

Data storage
Replatforming of scientific raw data undergoes a well-defined process through which it is systematically transformed through data pipelines into Tetra Data. To ensure data integrity and maintain organizational clarity, raw data and Tetra Data documents are meticulously stored in a dedicated S3 bucket. Tetra data pipelines and platform services always incorporate schema validation for each IDS document before the data is written to S3.
In its transition toward managing Tetra Data through Delta Tables, the responsibility for data validation will shift from the platform to frameworks and libraries that are accountable for reading and writing data to the lakehouse.
For Tetra Data that are already managed through Delta Tables, Tetra Data documents are directly written to these tables. The direct integration with Delta Tables ensures real-time availability of engineered data through catalog-managed Tetra Data Delta tables. This approach optimizes data accessibility and utilization within the TetraScience ecosystem.

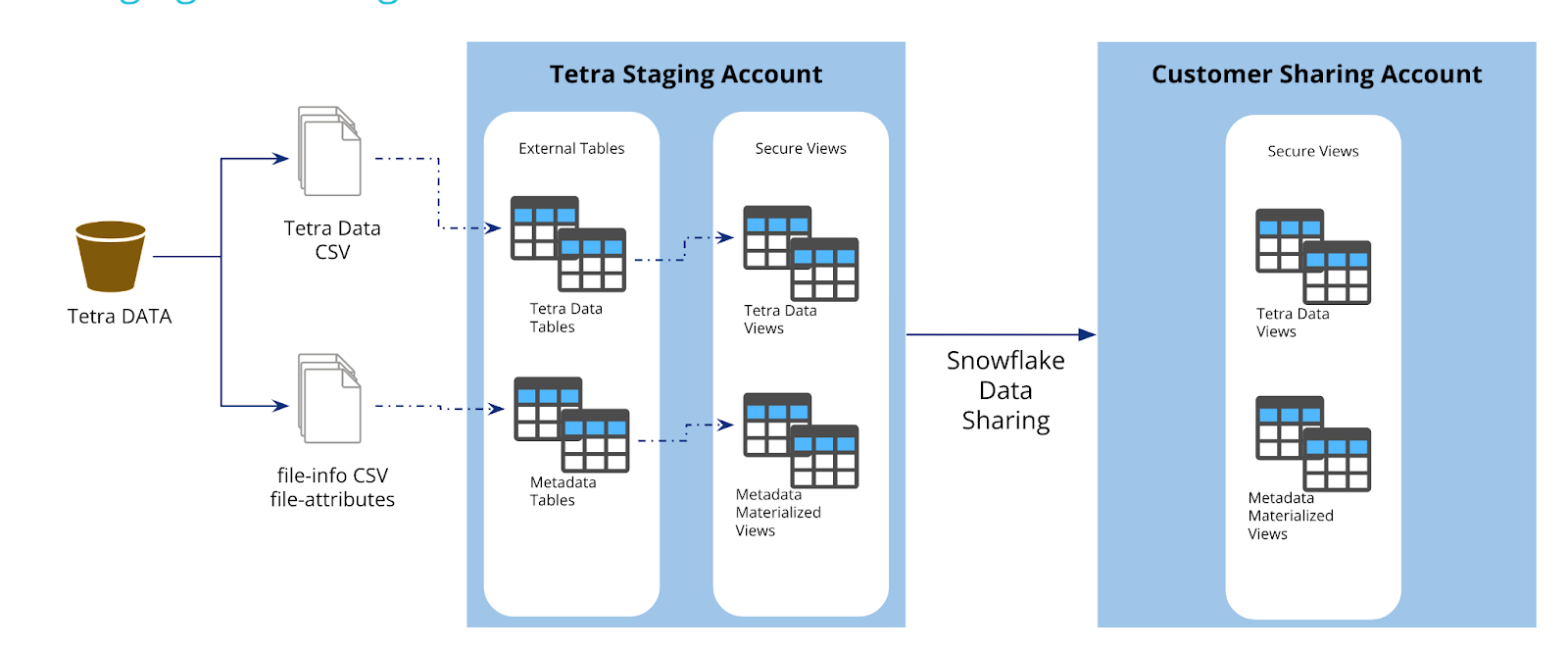
No data duplication
TetraScience's approach avoids data duplication. Instead of copying data, the Tetra Scientific Data Cloud enables external access to Tetra Data through the AWS Glue Data Catalog. By creating external tables, data remains in its original location within S3 buckets while the table definitions from the AWS Glue Data Catalog are shared with the customer's query engine of choice. For data sharing outside the organization, TetraScience will enable Delta Sharing in future platform releases. This open protocol enables cross-organization data sharing without duplication for a diverse set of clients including business intelligence tools such as Tableau and Power BI as well as programmatic SDK access using popular programming languages.
Accessing Tetra Data
TetraScience enables access to Tetra Data across various query engines while emphasizing data integrity and efficiency by avoiding data duplication. The AWS Glue Data Catalog acts as a central repository, ensuring consistent data definitions and accessibility, further enhancing the platform's data governance and performance capabilities.
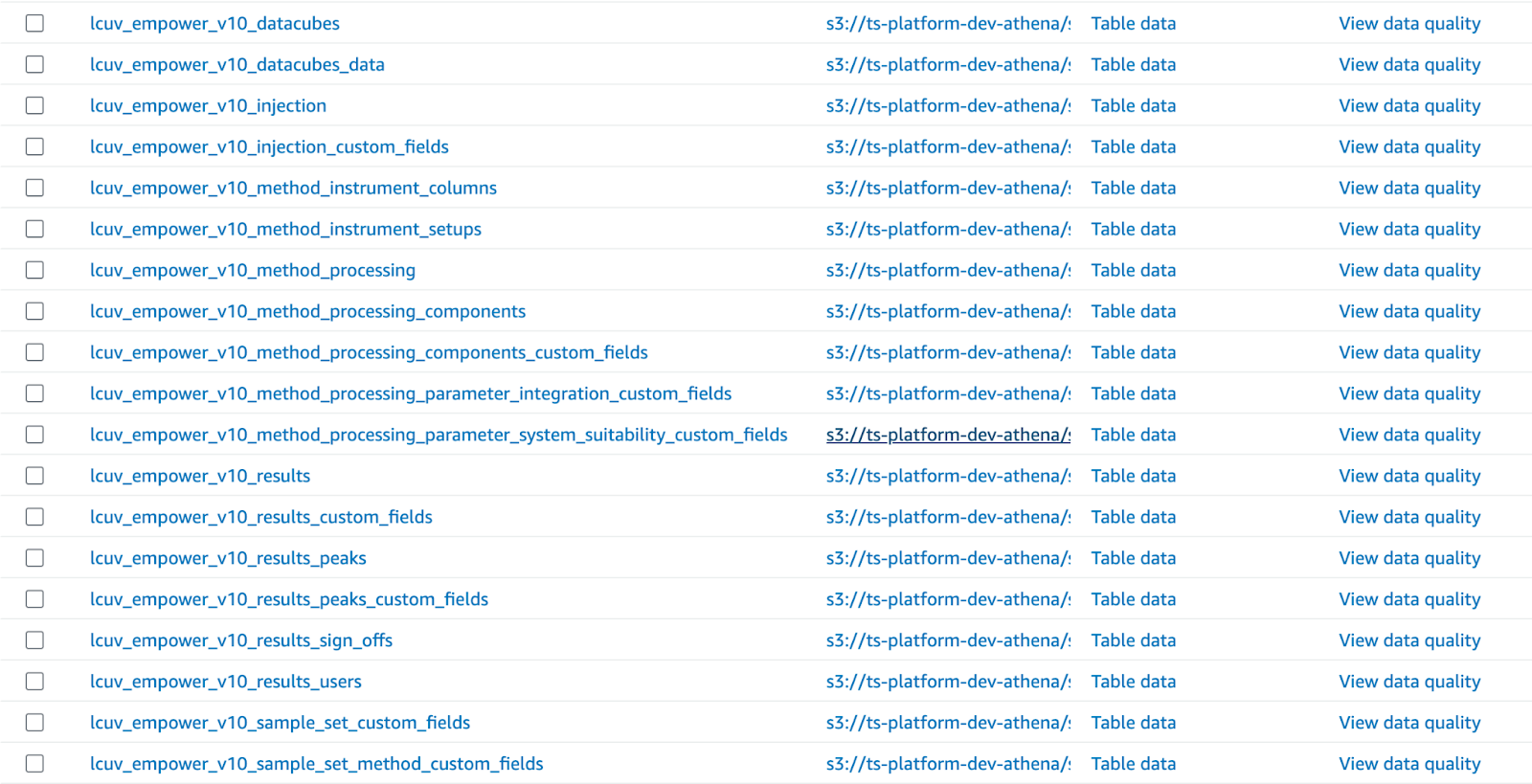
AWS Athena
Tetra Scientific Data Cloud natively supports AWS Athena, a serverless query service. Athena leverages the AWS Glue Data Catalog, serving as the default query engine for Tetra Data. The AWS Glue Data Catalog is the single source of truth for tabularized Tetra Data models, providing a consistent and reliable repository for table metadata. The SQL query interface embedded in the UI is powered by AWS Athena.
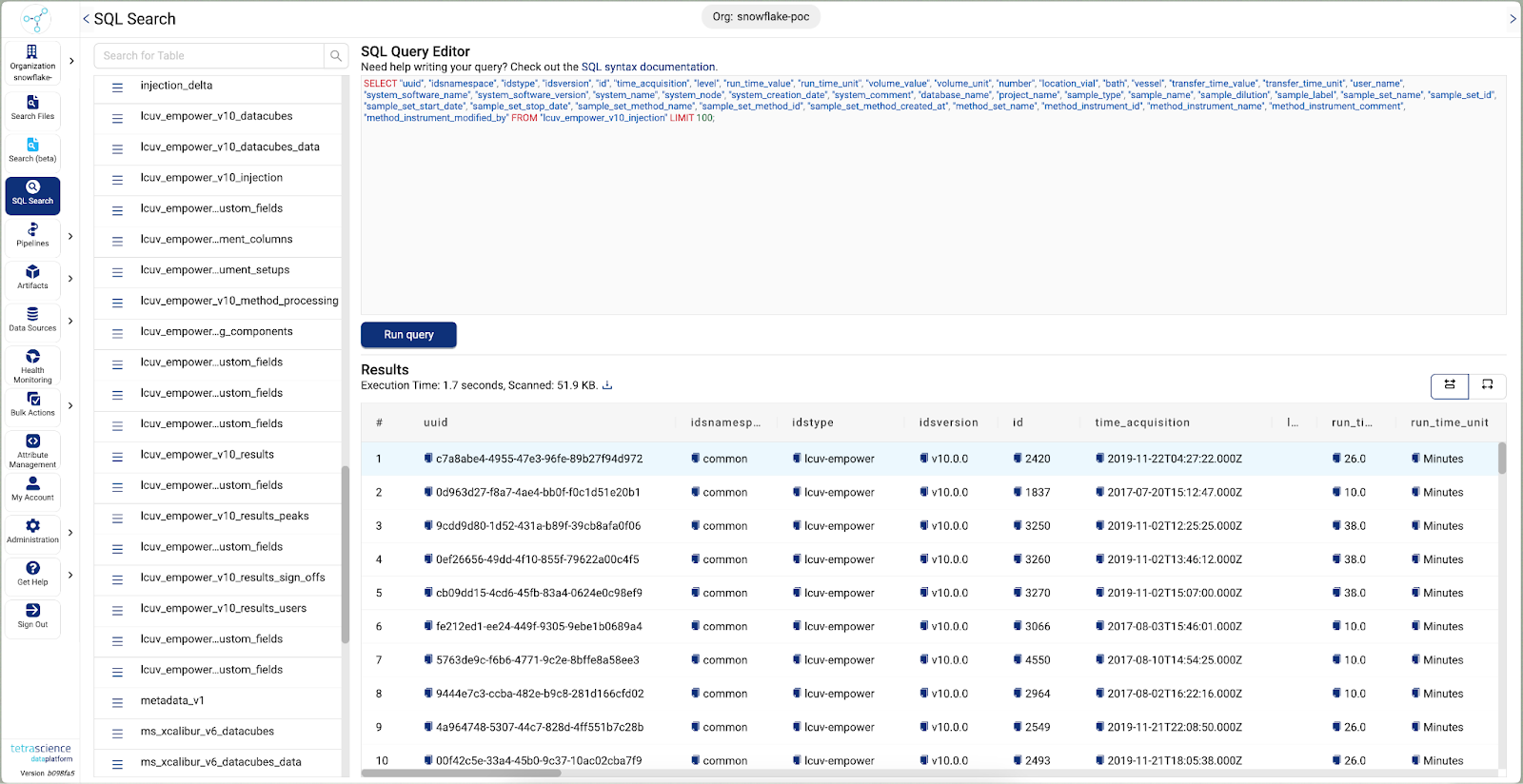
AWS Redshift
To facilitate data access from AWS Redshift, TetrasScience provisions Redshift Workspaces within customers' AWS accounts where the Tetra Scientific Data Cloud is deployed. Customers may choose to access data through Redshift Cross Account Data Sharing. Glue-managed Tetra Data table definitions are registered with Redshift, allowing seamless data querying directly from AWS S3. Again, the AWS Glue Data Catalog ensures data consistency and accessibility across platforms.
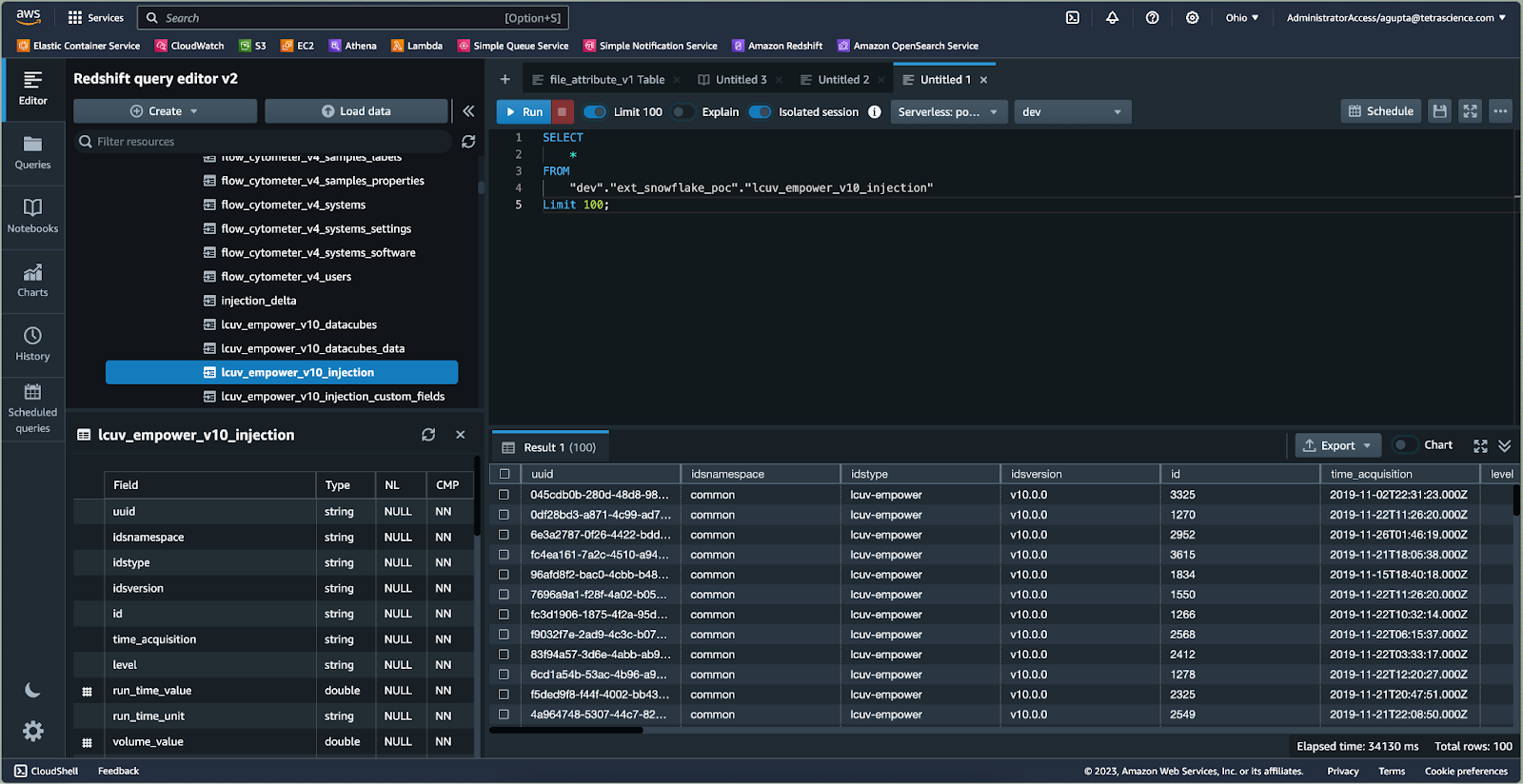
Snowflake
By setting up IAM permissions, the Tetra Scientific Data Cloud enables Snowflake to access data from S3 without data duplication. Glue Table definitions are registered as external tables in Snowflake, providing a direct link to Tetra Data. Data sharing is implemented through Snowflake's data sharing concept, isolating Snowflake warehouse credit usage and decoupling data storage, format, and S3 permissions.
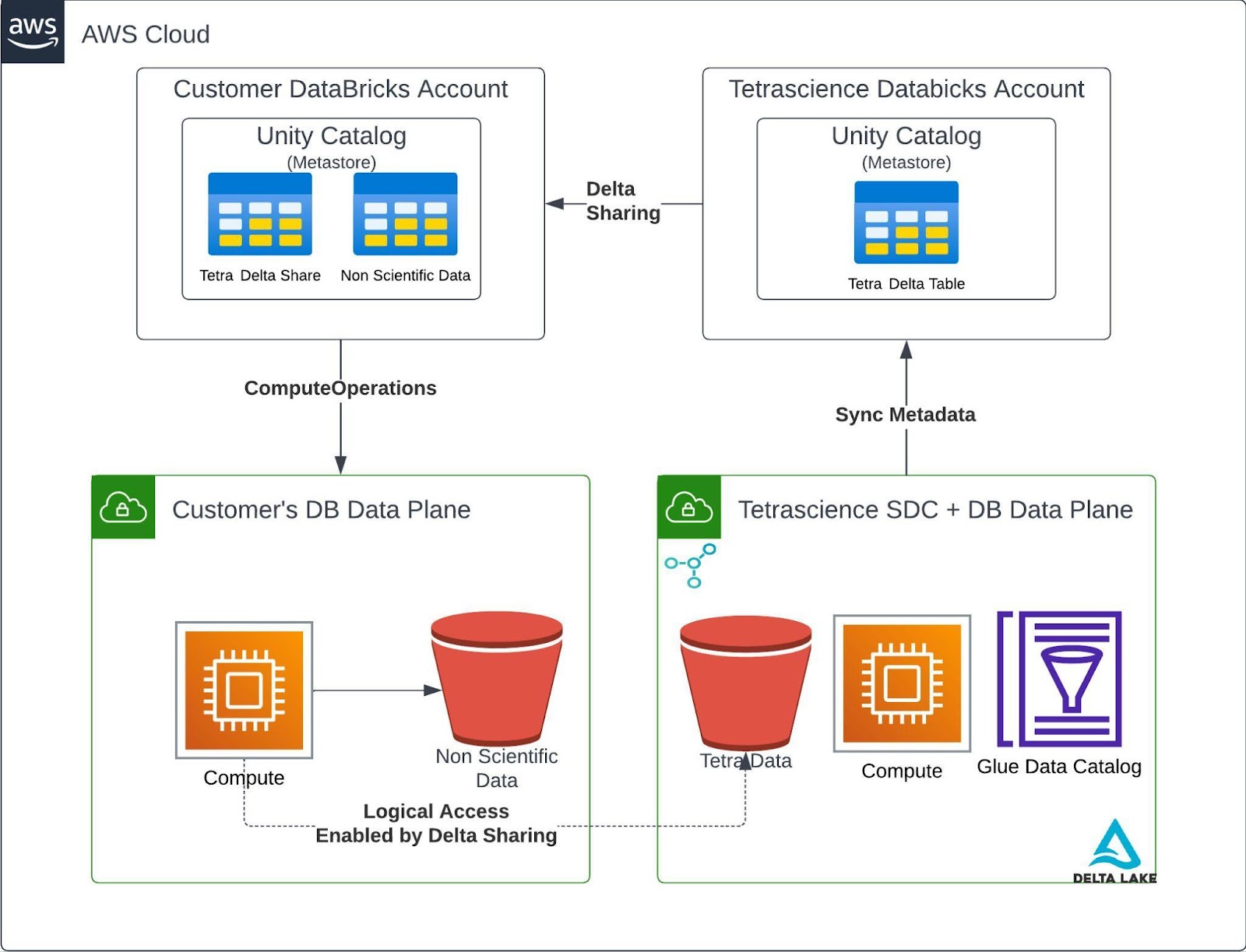
Databricks and Delta Lake
The transition of the Tetra Data Lake to Delta Lakehouse is expected to yield notable improvements in query performance, particularly when accessing external tables. This performance boost is especially significant for systems such as AWS Athena, Snowflake, and AWS Data Glue, which are inherently optimized for Iceberg Table definitions. These systems seamlessly interact with Delta Tables by leveraging the Delta Universal Format (Uniform). The TetraScience platform capitalizes on this feature by harnessing the power of the Uniform Delta Table, offering users high-performance data access without the necessity for data duplication.
Customers can look forward to experiencing minimal Delta write overhead when Uniform is enabled. This is because the Iceberg conversion and transaction processes occur asynchronously after the Delta commit. This approach streamlines data operations, ensuring that customers can work with their data efficiently and with enhanced performance while minimizing any potential disruptions during the data commit process.
Adopting Delta Lake enables TetraScience to provide seamless access to Tetra Data from Databricks.This integration expands compatibility and capabilities for users seeking to leverage Databricks for data analysis and processing for data analytics and AI.
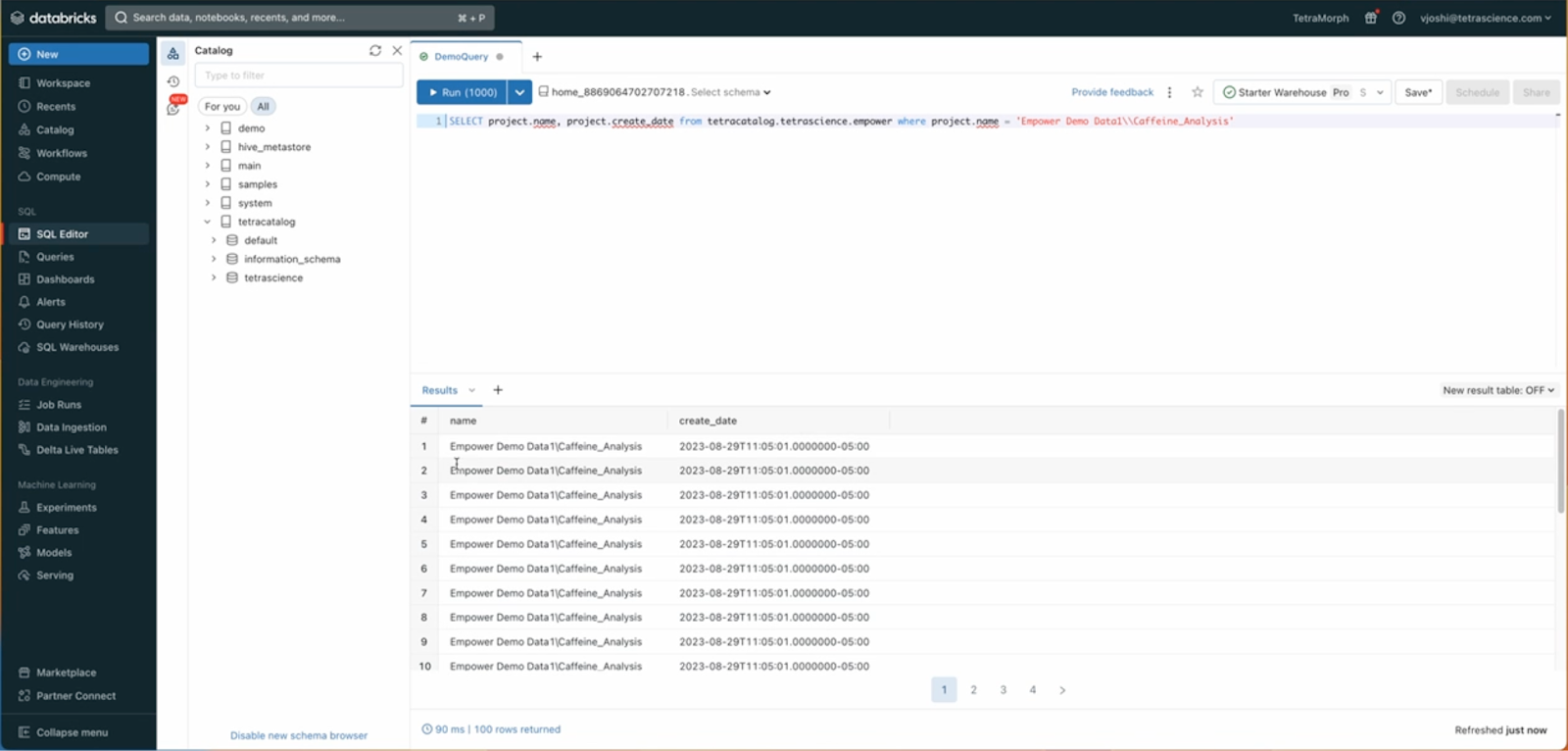
Final thoughts
The Tetra Scientific Data Cloud, along with its Delta Lakehouse architecture, is a game-changing solution for life science companies looking to modernize their data architecture, democratize data access, and leverage advanced technologies such as AI/ML while maintaining data governance and flexibility. With the unique approach and powerful features of the lakehouse paradigm, TetraScience is empowering data scientists and scientists to access engineered scientific data through SQL and integrate data in their day-to-day workflow. This will increase the scientific productivity of teams, reduce costs, and enable biopharmaceutical organizations to benefit from the power of AI to accelerate and improve scientific outcomes.